

Technical SEO is the most important part of SEO. At least up to a certain point. Pages need to be crawled, accessed and indexed to rank, but many other activities will have minimal impact compared to content (On-site SEO) and links (Off-site SEO).
This guide is aimed at the beginner and will help you understand some of the basics and where best to spend your time to maximize the impact.
Let's get started.
- Technical SEO basics
- Page Crawling
- Indexing
- Technical SEO quick wins
- Additional technical projects
- Technical SEO tools
Technical SEO basics
Since this is a beginner's guide, let's start with the basics.
What is technical SEO?
Technical SEO is the process of optimizing your website to help search engines like Google find, crawl, understand and index your pages. The goal is to be found and improve rankings in SERPs.
Is technical SEO complicated?
It depends. Mastering the basics is certainly not difficult, but technical SEO can be complex and difficult to understand.
Page Crawling
In this section, we'll look at how to ensure that search engines can effectively crawl your content.
How does page crawling work?
Crawlers take content from pages and use the links on those pages to find more pages. This allows them to find content on the web. There are several systems involved in this process, which is shortly explained below.

URL sources
A crawler has to start somewhere. Typically, it would create a list of all the URLs it would find through page links. A secondary system for finding more URLs is site schemas created by users or by various systems that have lists of pages.
Crawl queue
All URLs that need to be crawled or re-crawled are prioritized and added to the crawl queue. This is essentially a list of ordered URLs that Google wants to crawl.
Crawler
A system, or usually cold robot, that fetches and crawls the content of pages.
Processing systems
These are the various systems that process canonicalization, send pages to a renderer, which loads the page as a browser, and process the pages to get more URLs to check.
Renderer
The renderer loads the page as a browser with JavaScript and CSS files. This is done so that Google can see what most users will see.
Index
These are the stored pages that Google shows to users.
Crawl controls
There are a number of ways to control what gets crawled on your website. Here are some options.
1. Robots.txt
The robots.txt file tells search engines where they can and cannot go on your site.
Google may index pages that it cannot check if links point to those pages. This can be confusing, but if you want to prevent pages from being indexed, check out this guide and flowchart to help you through the process.
2. Crawl rate
The robot.txt file contains a crawl delay directive that is supported by many checkers. It allows you to set how often they can check pages. Unfortunately, Google does not respect this. "In Google's case, you will have to change the Google Search Console's crawl frequency as described here.
3. Access restrictions
If you want a page to be accessible to some users but not to search engines, you probably want one of these three options:
- A specific login system;
- HTTP authentication (where access requires a password);
- IP whitelisting (which only allows specific IP addresses to access pages).
These types of tools are best suited for internal networks, for members-only content, or when designing, testing or developing websites. It allows a group of users to access a page, but search engines will not be able to reach them and will not index the pages.
How to see crawling activity
The easiest way to see what they are crawling on Google is the Google Search Console "Crawl Stat" report, which gives you more information about how they are crawling your website.
If you want to see all the crawling activity on your website, you will need to access the server logs and possibly use a tool to better analyze the data. This can be quite advanced, but if your hosting has a control panel such as cPanel, you should be able to access the raw logs and some aggregators such as Awstats and Webalizer.

Crawl adjustments
Each website will have a different crawl budget - a combination of how often Google wants to crawl your website and how much your website allows. More popular pages and pages that change frequently will be crawled more often, while pages that don't seem popular or don't have links will be crawled less often.
If crawlers see signs of stress when checking a site, they will usually slow down or even stop checking until conditions improve.
Once the pages have been crawled, they are submitted and sent to the index. The index is a master list of pages that can be submitted for search queries. Let's talk about the index.
Indexing
In this section, we'll talk about how to make sure your website pages are indexed and check how they are indexed.
Robots directives
A robot meta tag is a snippet of HTML that tells search engines how to crawl or index a particular page. It is embedded in a section of a web page and looks like this:
<meta name="robots" content="noindex" />Canonicalization
When there are multiple versions of the same page, Google will choose one to store in its index. This process is called canonicalization, and the URL chosen as the canonical URL will be the one that Google will show in its search results. There are a number of different signals they use to select a canonical URL, including:
- Canonical tags
- Repeating pages
- Internal links
- Redirects
- Sitemap URLs
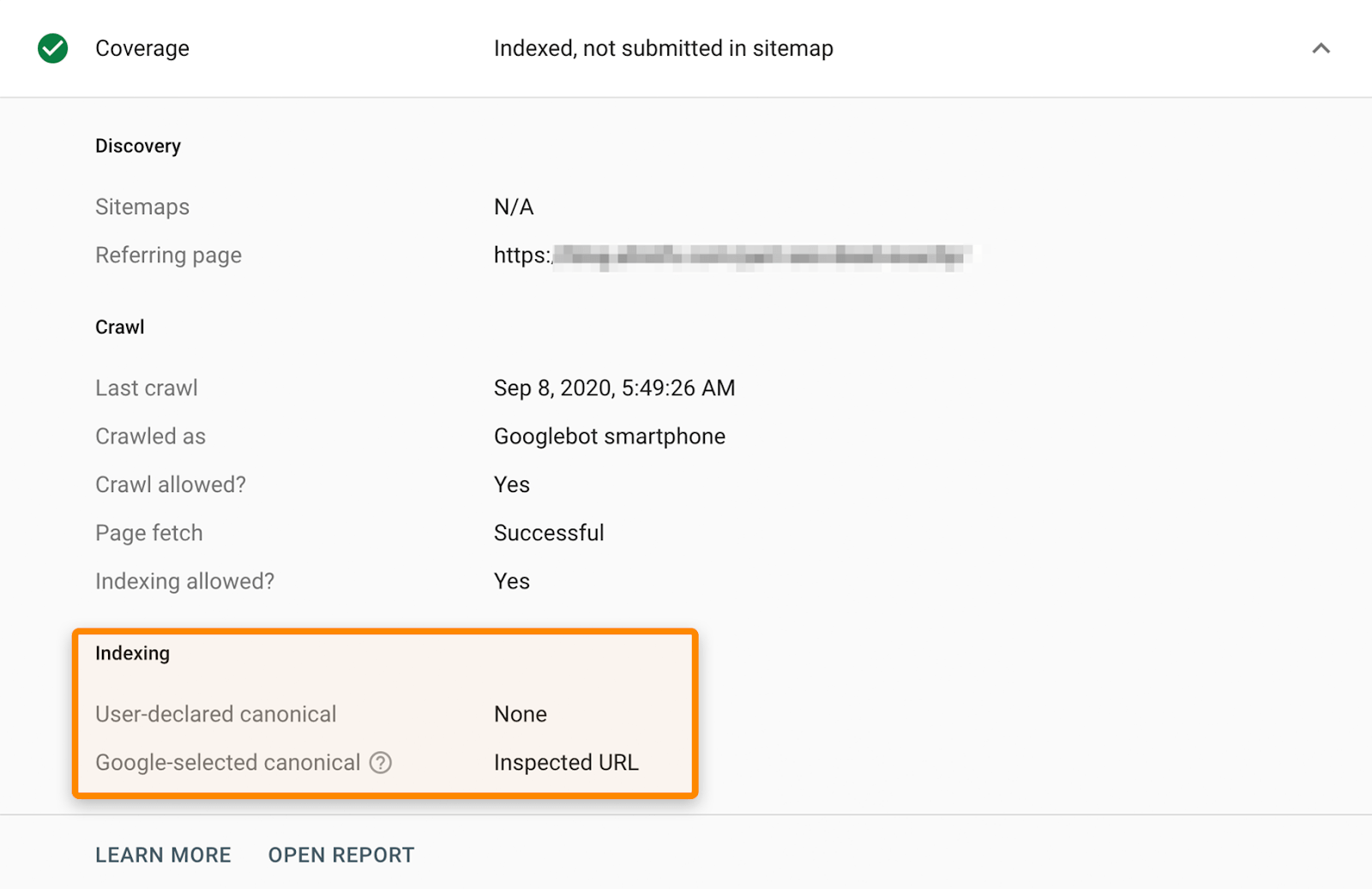
The easiest way to find out how Google has indexed a page is to use the URL Inspection Tool in the Google Search Console platform. It will show you the canonical URL selected by Google.
Technical SEO quick wins
One of the hardest things in SEO process is prioritizing. There are many best practices, but some changes will affect your rankings and traffic more than others. Here are some of the projects I would recommend giving priority to.
Check indexing
Make sure the pages you want people to find can be indexed by Google. The previous two chapters have talked about checking and indexing, and this was no coincidence.
You can check the Site Audit indexing report to find the pages that can't be indexed and the reasons for this. You can do this for free in Ahrefs Webmaster Tools.
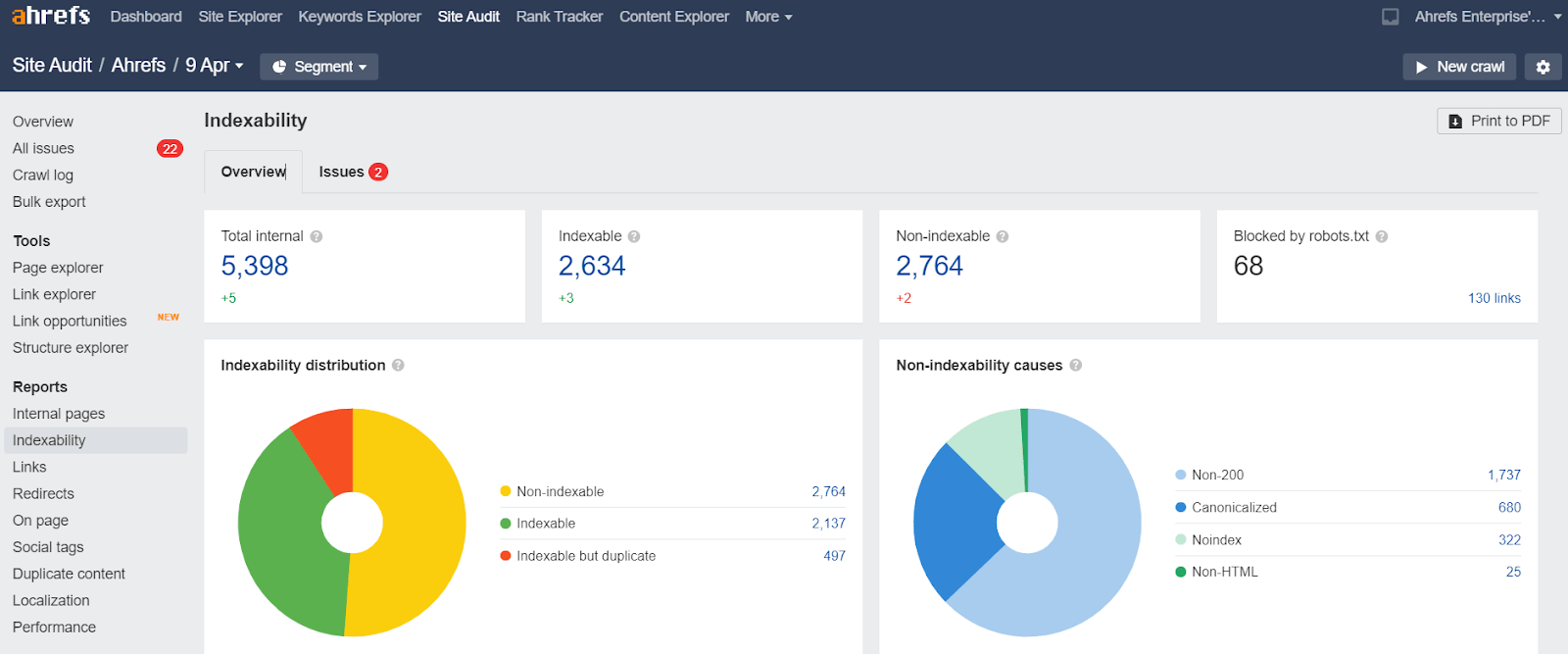
Recover lost links
Over the years, websites tend to change their URLs. In many cases, these old URLs contain links from other websites. If they are not redirected to your current pages, these links are lost and no longer count on your pages. It's not too late to make these redirects and you can quickly recover the lost value. Think of it as the fastest link building you will ever do.
Site Explorer -> yourpage.com -> Pages -> Best By Links -> add HTTP response filter "404 not found". We usually sort by "Reffering Domains".
This is how 1800flowers.com looks like.
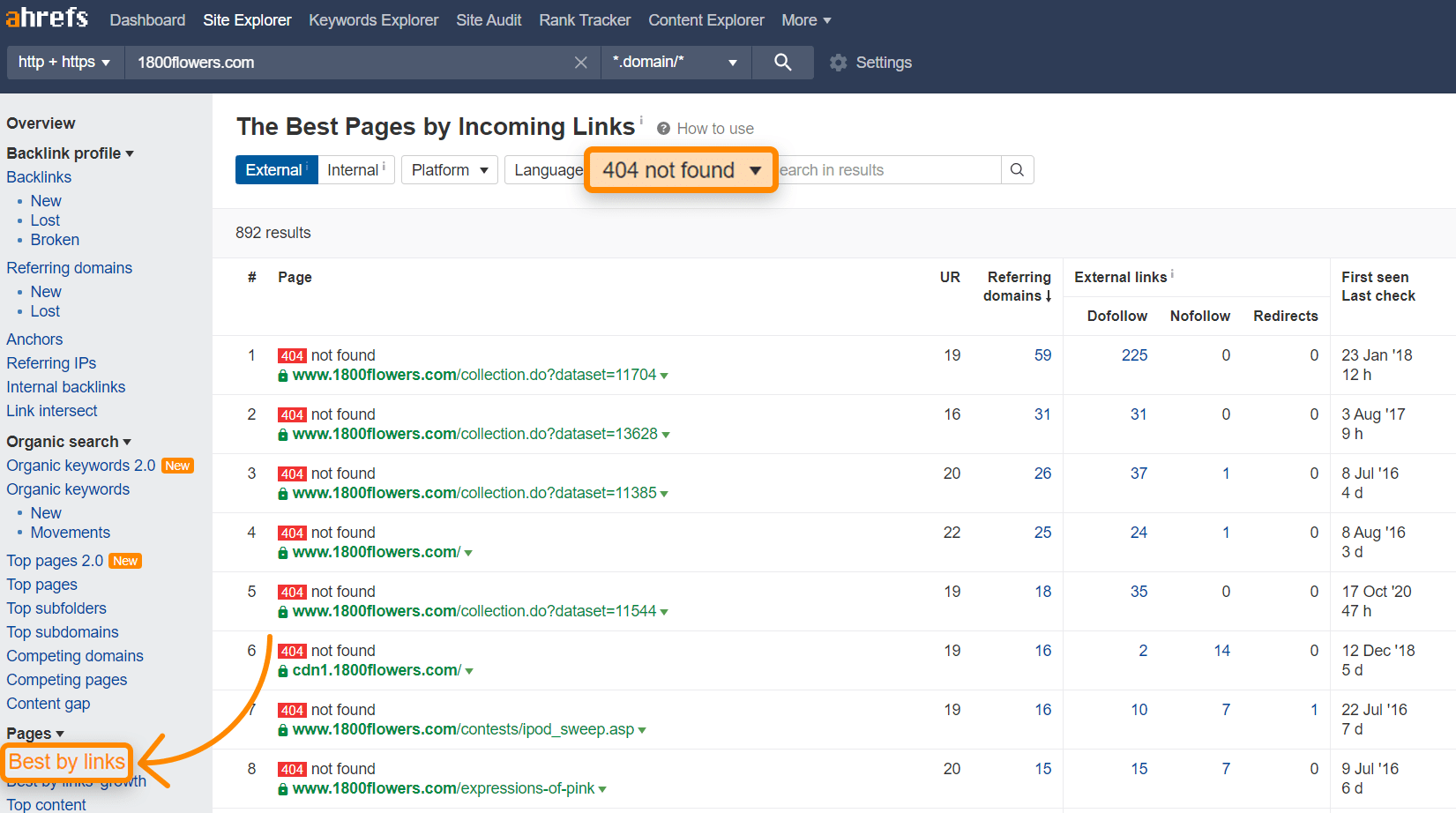
Looking at the first URL, archive.org, we can see that it used to be a Mother's Day page. By redirecting that one page to the current version, you would recover 225 links from 59 different sites, and there are even more possibilities.
You'll want to 301 redirect all the old URLs to their current locations to recover the lost value.
Add internal links
Internal links are links from one page of your website to another page of your website. They help your pages to be found and help your pages to rank better. There is a tool in Site Audit called "Link opportunities" that helps you find these opportunities quickly.
Add schema markup
Schema markup is a code that helps search engines better understand your content and provides a number of features that can help your site stand out in search results. Google has a search gallery that shows the different search features and schema required to make your website relevant.
Additional technical projects
All the projects summarized in this section are good things to focus on, but they may require more work and have less benefit than the quick-win projects in the previous section. This doesn't mean you shouldn't do them, it's just to help you understand how to prioritise the different website optimisation projects.
Page experience signals
These have less influence on ranking factors, but you still want to pay attention to them for the benefit of your users. They include aspects of your website that affect the user experience (UX).
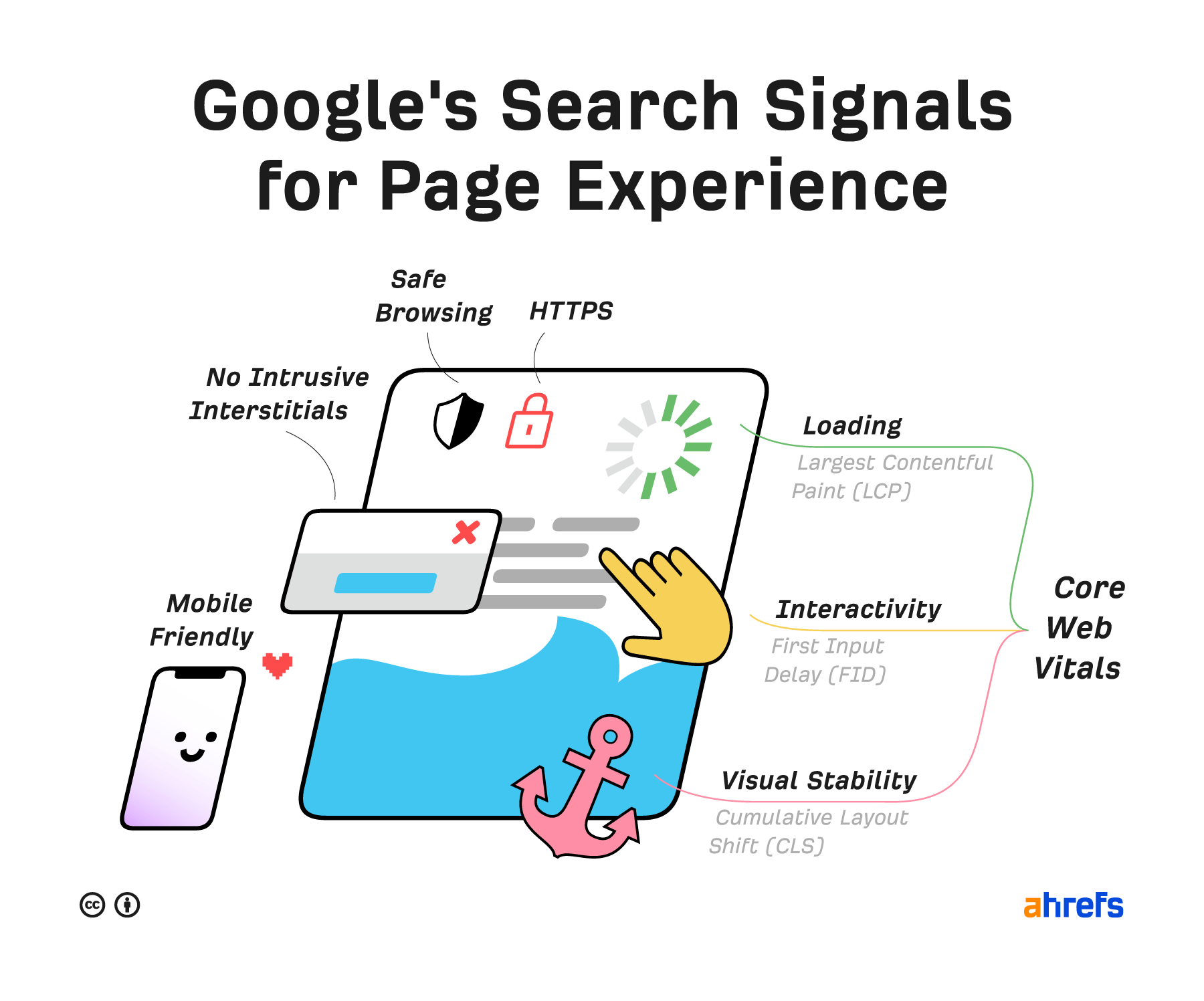
Core Web Vitals
Core Web Vitals are speed metrics that are part of Google's Page Experience Signals used to measure user experience. The metrics measure visual load with Largest Contentful Paint (LCP), visual stability with Cumulative Layout Shift (CLS) and interactivity with First Input Delay (FID).
HTTPS
HTTPS secures the connection between the browser and the server to prevent attackers from intercepting and corrupting your page. This ensures the confidentiality, integrity and authentication of much of today's WWW traffic. You want your pages to load over HTTPS, not HTTP.
Any site that displays a lock icon in the address bar uses HTTPS.

Mobile friendliness
Simply put, this checks that web pages display properly and are easy to use on mobile devices. And it is important since Google uses mobile page version as main version to judge the page.
How do you know if your website is mobile-friendly? Check the Mobile Usability report in Google Search Console.
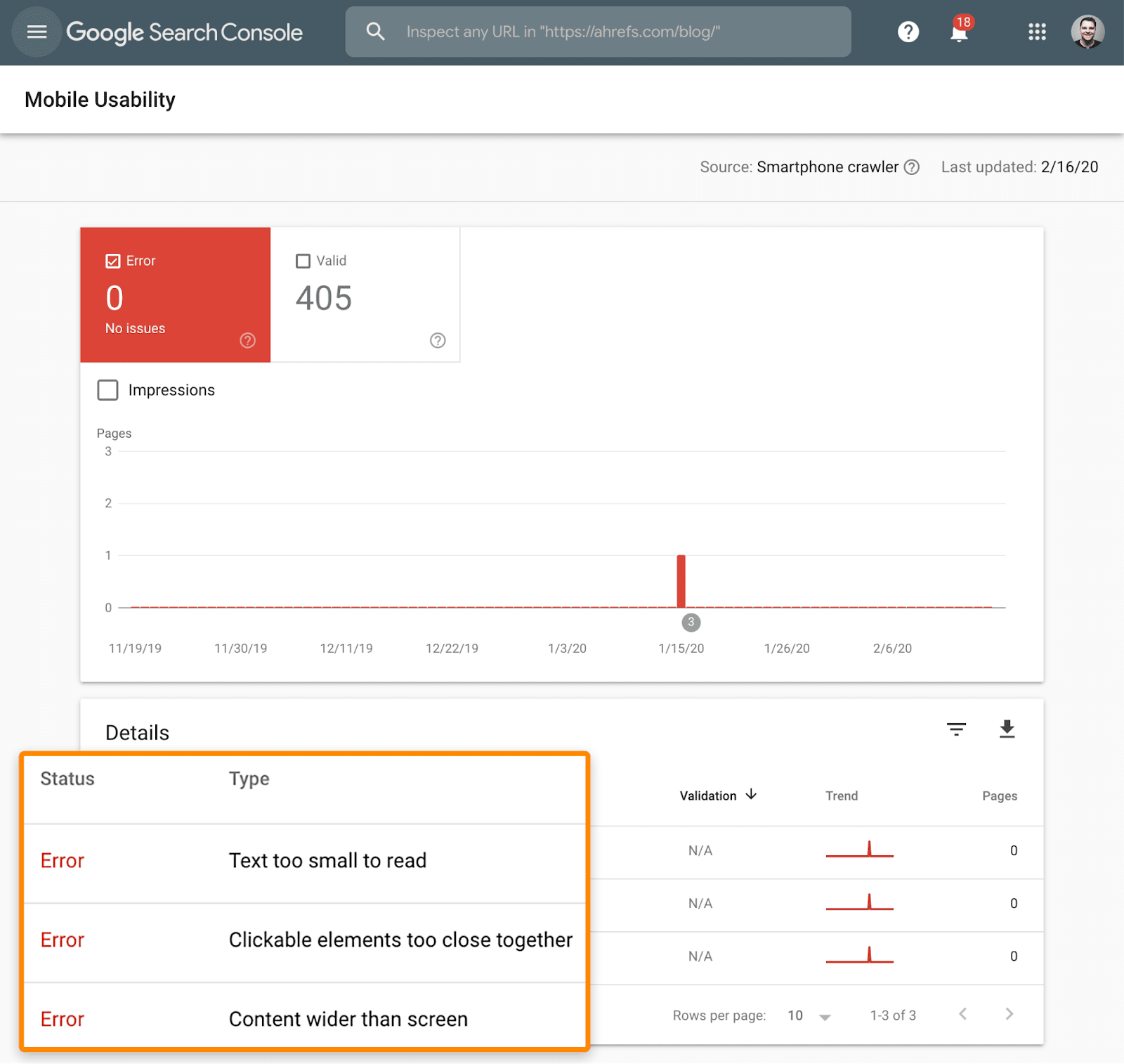
This report shows whether any of your pages are experiencing problems with mobile-friendliness.
Safe browsing
These are checks to make sure that pages are not fraudulent, free of malware and downloads.
Proxy page ads
Interstitials prevent the content from being read. These are pop-ups on top of the main content that users may have to interact with before they disappear.
Hreflang - for multiple languages
Hreflang is an HTML attribute used to indicate the language and geographic scope of a web page. If you have multiple versions of the same page in different languages, you can use the hreflang tag to tell search engines such as Google about these variations. This helps Google to provide the correct website version to its users.
General maintenance / website status
These tasks are unlikely to have a significant impact on your rankings, but usually need to be addressed for a better user experience.
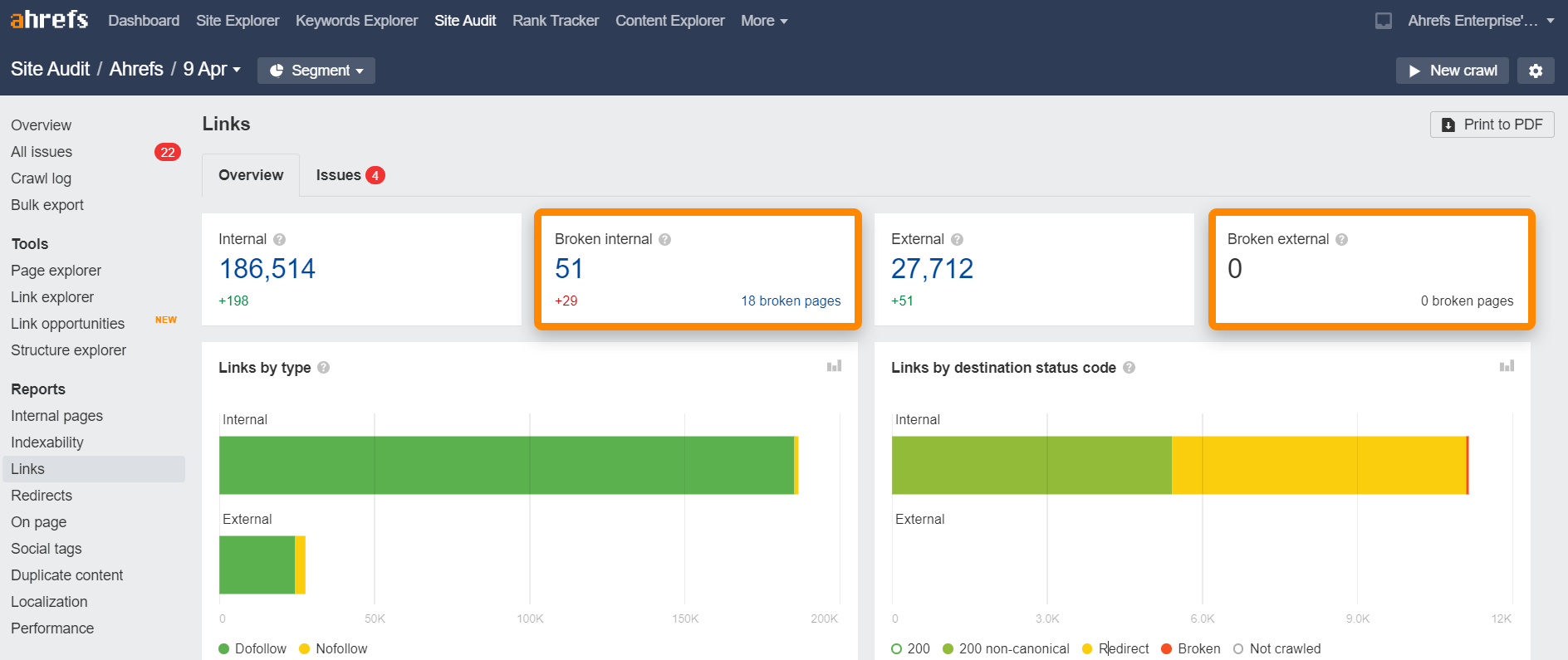
Broken links
Broken links are links on your website that point to resources that do not exist - these can be internal (i.e. to other pages on your domain) or external (i.e. to pages on other domains).
You can quickly find broken links on your website using the Site Audit link report. You can do this for free in Ahrefs Webmaster Tools.
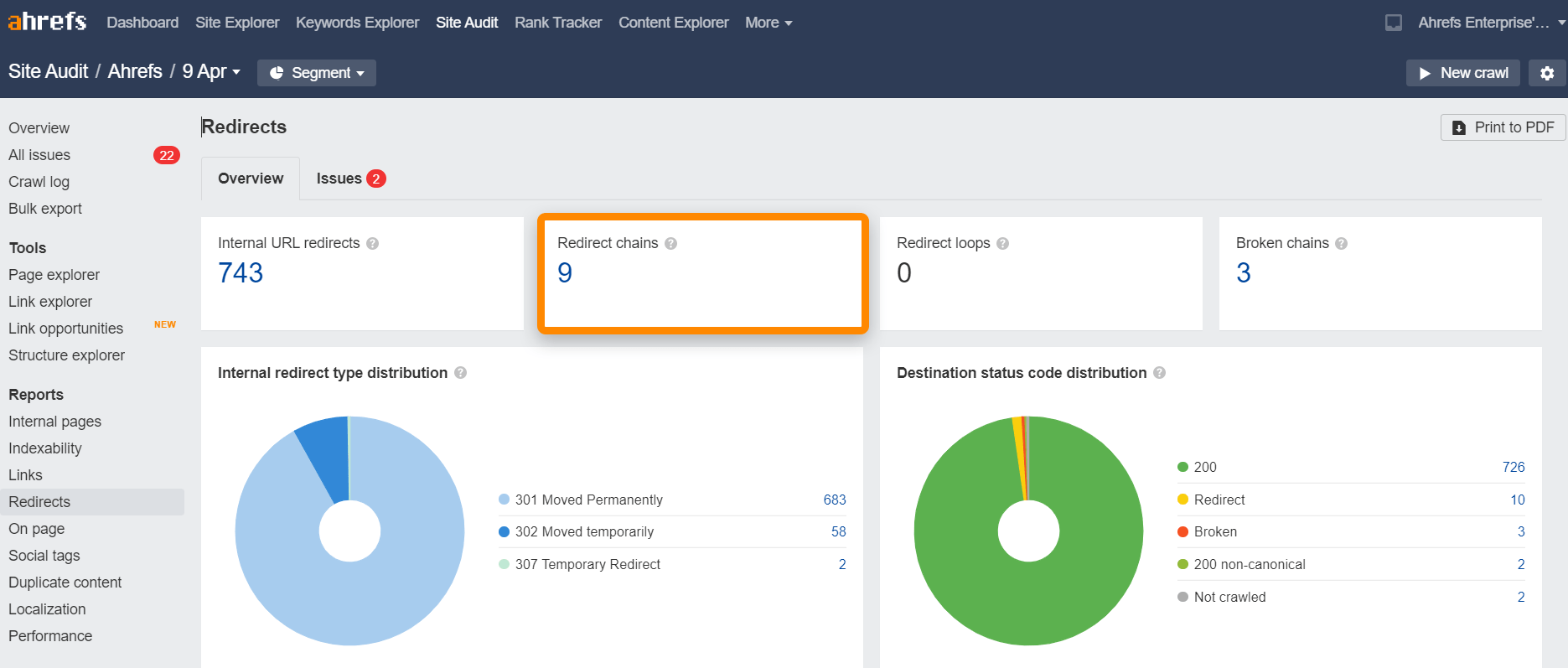
Redirection chains
Redirect chains are a series of redirects that take place between the source URL and the destination URL.
You can quickly find redirect chains on your website using the Site Audit redirect report. You can do this for free in Ahrefs Webmaster Tools.
Techninio SEO įrankiai
Šie įrankiai padeda analizuoti ir pagerinti aptartus techninius svetainės aspektus.
Google Search Console
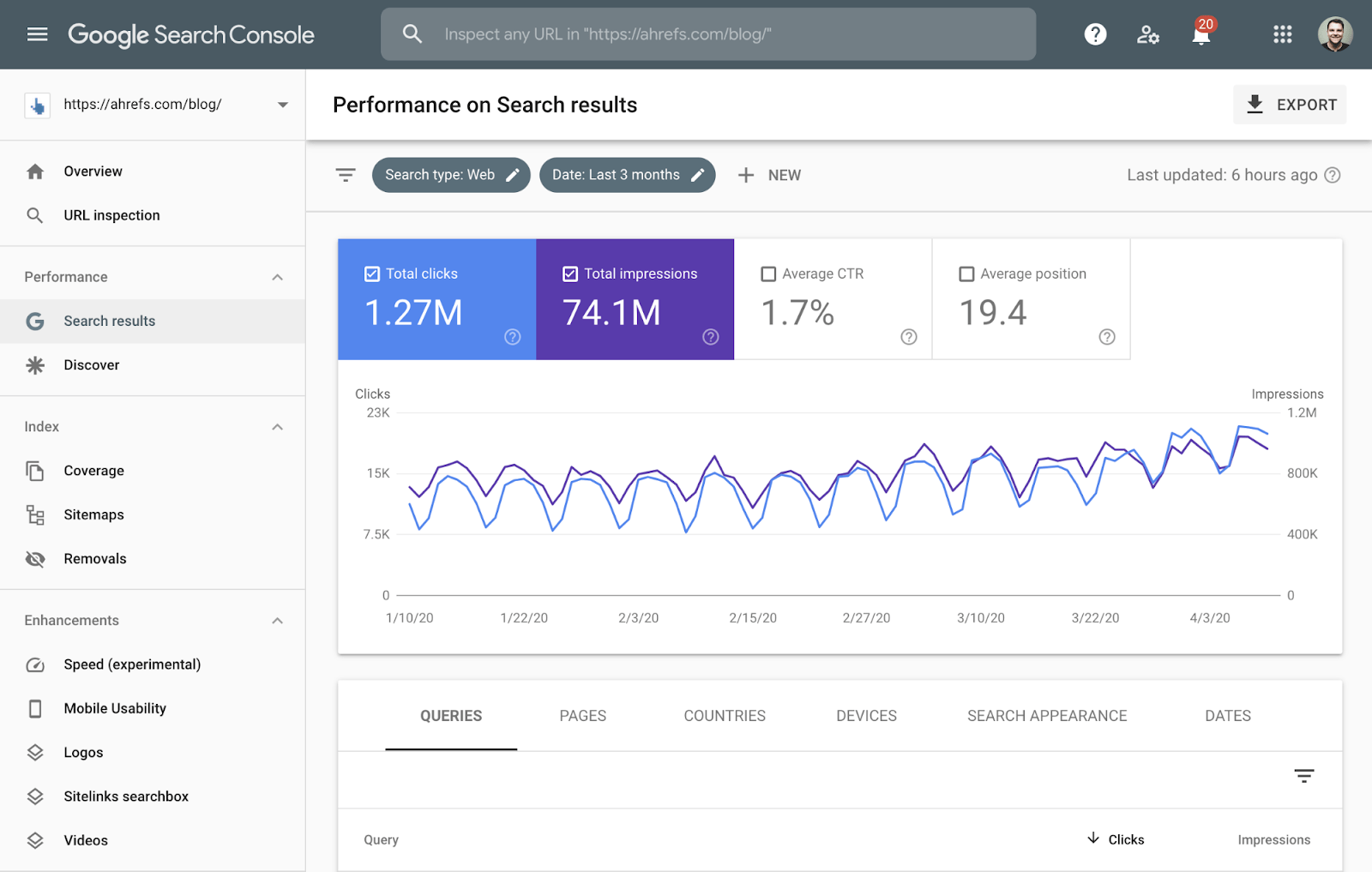
Google Search Console (formerly known as Google Webmaster Tools) is a free service from Google that helps you monitor and manage the appearance of your website in search results.
Use it to find and fix technical errors, provide site diagrams, review structural data issues, and more.
Google Mobile-Friendly Test
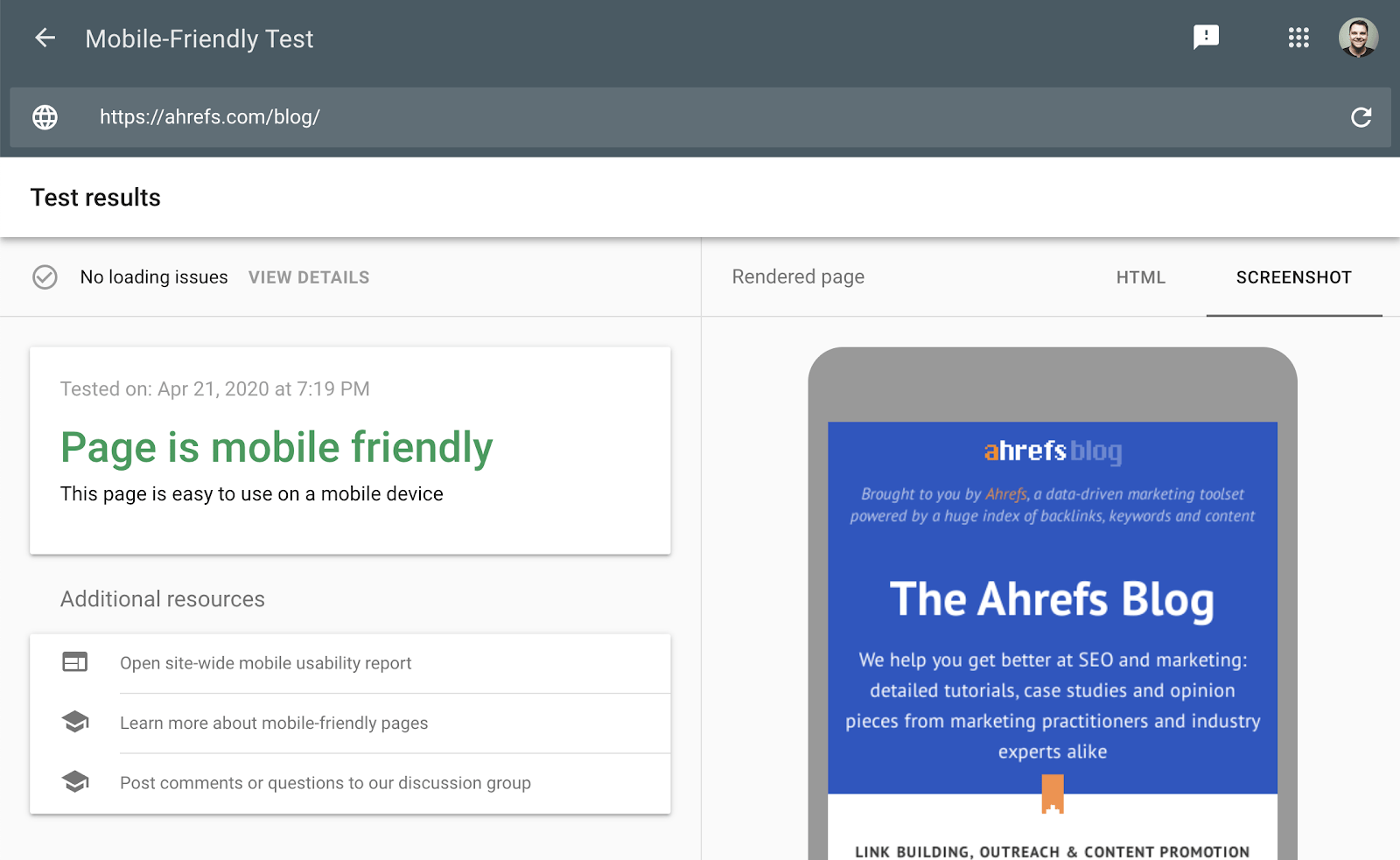
This test checks how easy it is for a visitor to use your site on a mobile device. It also identifies specific mobile usability issues, such as text that is too small, the use of incompatible plugins, etc.
The mobile-friendliness test shows you what Google sees when it checks a page. You can also use the Rich Results Test to see the content Google sees on desktop or mobile devices.
Chrome DevTools
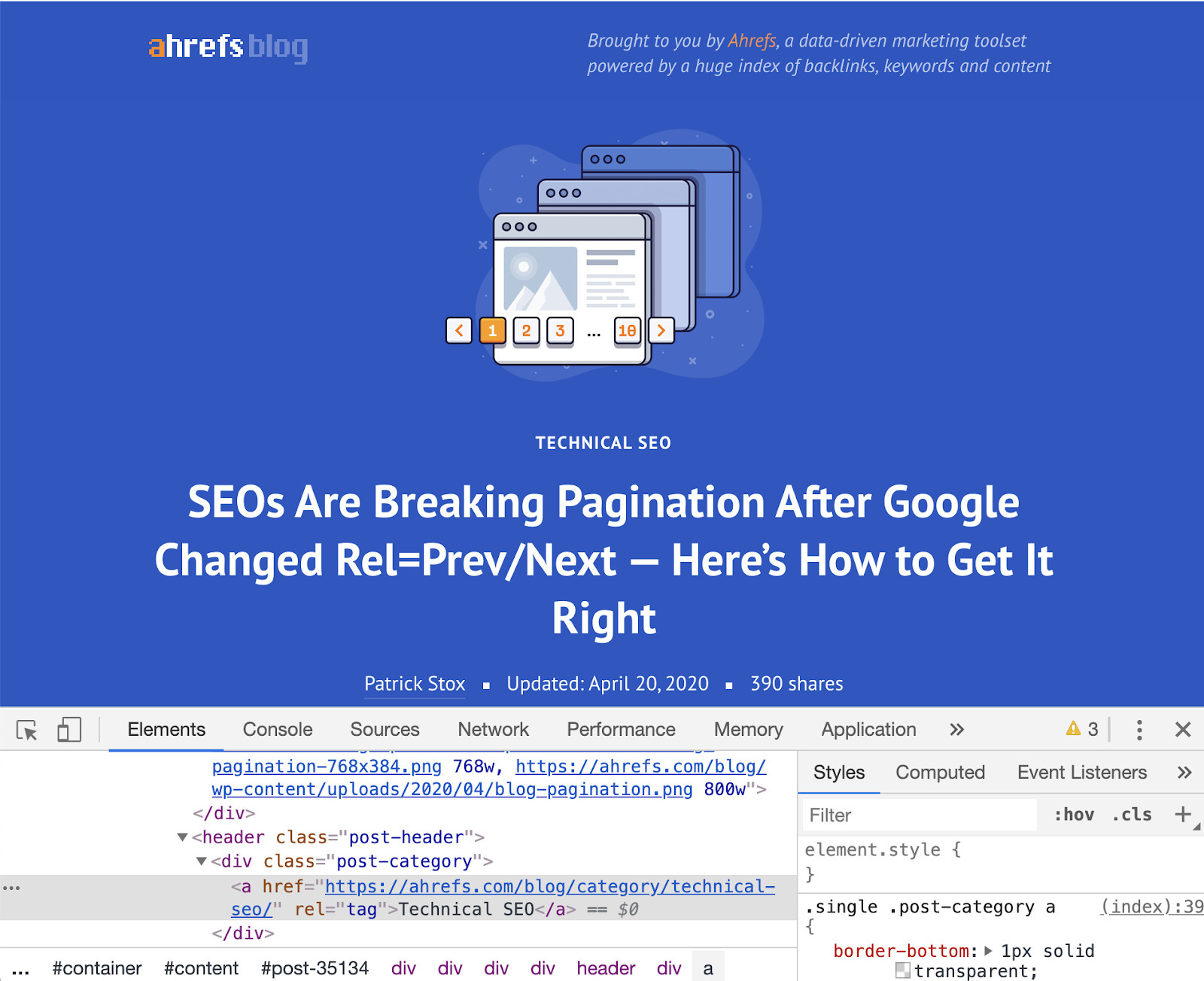
Chrome DevTools is Chrome's built-in web debugging tool. Use it to identify page speed issues, improve web page performance and more.
From a technical SEO point of view, it has endless uses.
Ahrefs Toolbar
Ahrefs SEO Toolbar is a free extension for Chrome and Firefox that provides useful SEO data about the pages and websites you visit.
The tool's free features include:
- Page SEO Report
- Redirect tracker with HTTP headers
- Broken link checker
- Link Crawler
- SERP positions
In addition, as an Ahrefs user, you get:
- SEO metrics for every website and page you visit and Google search results
- Keyword metrics, such as search volume and keyword severity, directly in SERPs
- Export of SERP results
PageSpeed Insights
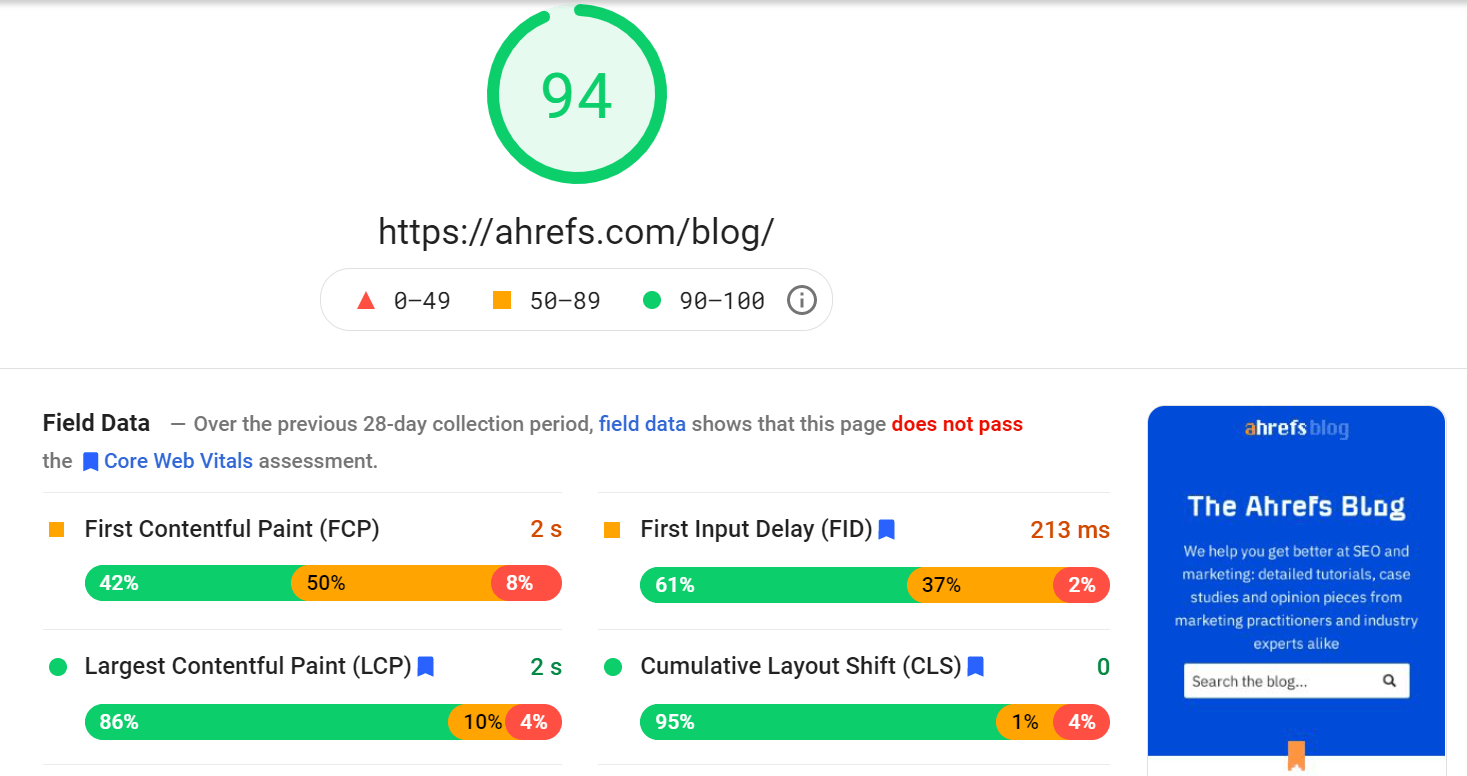
PageSpeed Insights analyzes the loading speed of your website. In addition to the performance score, it also gives you actionable recommendations on how to make your pages load faster.
And last
All of this only touches the surface of technical SEO. This information should help you understand the basics and be a starting point to your technical SEO journey.
Adapted from original text by Patrick Stox The Beginner's Guide to Technical SEO.

